
Speaker : อาจารย์ มิว Data Engineer จาก CJ ควบตำแหน่ง GDE: Google Developer Expert คนล่าสุดของประเทศไทย และ DataRockie อาจารย์ ทอย Kasidis Satangmongkol
Date : 2 Mar 2025
เรียน+รับฟรี หมวก กระเป๋า google ตั้งแต่วันที่ 27 กุมภาพันธ์ – 29 มีนาคม 2568
https://rsvp.withgoogle.com/events/chaiyogcp-s5/home
กิจกรรม Technologista: International Women’s Day Bangkok 2025
Mar 22, 1:00 – 6:00 PM (GMT+7)
Cleverse, ถนน รัชดาภิเษก, Bangkok, 10310
https://gdg.community.dev/events/details/google-gdg-cloud-bangkok-presents-technologista-international-womens-day-bangkok-2025/
/////
- Intro to Data Engineering
- Which position do I stand ?
- Structure
- Databases
- ทำ Project มาเขียนเป็น blog
- Mindset สำคัญมาก
- Read
- Write
Intro to Data Engineering
ทำไมต้องมี DE
ต้องขอสิทธิในการเข้าถึง data ปรับปรุงข้อมูลให้พร้อมนำไปใช้ ส่งมอบให้ผู้ใช้คนต่อไป เช่น DA เพื่อวิเคราะห์ข้อมูล
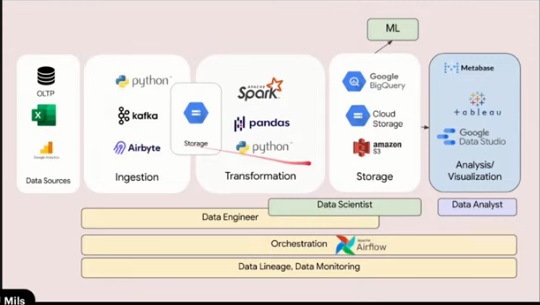
Data Engineering Life Cycle
1.Pipeline
2.Components
4 stage in data pipeline
Ingestion ต้นทาง (Data Lake) => Transformation => Storage (Data Warehouse) <= Analysis (Analyst/ML/Engineer)
Data Lake ข้อมูลดิบ
Data Warehouse ข้อมูลที่จัดเรียงเตรียมนำไปใช้ได้
Data Mart
ETL Extract Transform Load
ดึงข้อมูลมาจากแหล่งข้อมูล มีการทำ transform ไปเก็บที่ Data Warehouse
ELT Extract Load Transform เป็นที่นิยมในปัจจุบัน สามารถ track ย้อนหลังได้
ดึง Data มากองไว้ก่อน เพื่อให้มี Raw Data และทำ transform ไปเก็บที่ Data Warehouse
ค่าเก็บข้อมูลใน could มีส่วนหนึ่งไม่แพง แต่ค่าดึงข้อมูลมาใช้ต้องจ่ายอีกส่วนหนึ่ง
จากข้อมูลใหญ่ สามารถเลือกดึงข้อมูลแบบใหญ่ หรือ เล็ก ได้ เลือกให้เหมาะสมกับการใช้งาน
Which position do I stand ?

Structure
Unstructured data = text audio video PDF IoT sensor data
Semi-structured data = XML , CSV, JSON, Web pages
Structure data = PostageSQL , MySQL
Databases
Relational (SQL) , Traditional database/DMBS , table , row-oriented
: PostageSQL , MySQL , SQLite
Non-relational (NoSQL) , Not only SQL , อ่านแนวตั้ง ,
Columnar : apache HBASE , cassandra
Key-Value : redis , amazon dynamoDB ,
Cocument : mongoDB couchDB ,
Graph :neo4j
OLTP online transaction processing หน้าบ้าน เขียน ตู้เอทีเอ็ม
OLAP online analytical processing หลังบ้าน อ่าน รายงานประจำเดือน
Scenario

Gemini ; Explain the difference between OLTP and OLAP , keep you answer shot concise, and use bullet point, in table format
Data Lake = Unstructured , semi-structured , structured
Data Warehouse = structured
Data Lakehouse = รวม
Orchestration ตั้งค่าทำงานอัตโนมัติ
Software Engineer
DA ควรรู้ SQL JVM, Scala Python Bash
Spark Pandas Numpy Airflow Sudo
Infrastructure as a Code
Container : Docker Bubenetes
Provisioning : Terraform Git
Security ใครเป็นเจ้าของ สามารถเข้ามาดู แก้ไข ระดับการเข้าถึง
Data Architecture
เข้าใจธุรกิจ การเกิด ความต้องการ เพื่อนำมาปรับ design ในการ serve data อย่างไร
On premises VS Cloud
ซื้อ หรือ ใช้ Cloud อยู่ที่ธุรกิจ และ คุ้มทุน
Serverless มีคนช่วยดูแลให้
Hybrid and multi-cloud อยู่ที่ทีมผู้ใช้ สะดวกแบบไหน
Data Governance / Data Management
Data Monitoring ตั้งค่าเตือน
Data Discovery & Data Catalog บันทึกข้อมูล คนอื่นๆ สามารถมาดูได้
Data Lineage บันทึกความสัมพันธ์ของ data
Data Quality ส่งข้อมูล ที่สำคัญ ไม่เอาขยะ
How do I become Data Engineer ?
Modern Data Engineer Roadmap 2021
https://github.com/datastacktv/data-engineer-roadmap
ทำ Project มาเขียนเป็น blog
มีเป้าหมายอยากจะทำอะไร เช่น วิเคราะห์ social media data
จะเอา data มาจาก social media ได้อย่างไร
มีเครื่องมือให้ connect และดึงมาใช้ได้ ทดลองใช้ฟรี 14 วัน https://supermetrics.com/
หรือให้ Gemini ช่วย ;
Create a sample dataset for RFM modeling (segmentation). Example in retail business.
Can you give me a new code to generate example dataset in Banking business in RFM modeling
Mindset สำคัญมาก
Read
https://medium.com/
https://www.oreilly.com/online-learning/
Write
Notion
https://mesodiar.com/
https://mesodiar.medium.com/
AI + Prompt
เพื่อนๆ อ่านแล้ว มีข้อคิดเห็นอย่างไร ช่วยบอกด้วยค่ะ


